{
"type": "note",
"title": "Web Development Basics",
"tags": [
"post",
"Web"
],
"sources": [
"xlog"
],
"external_urls": [
"https://desmond-lsg.tech/web-dev-basics"
],
"date_published": "2023-02-09T00:00:00.000Z",
"content": "---\ntitle: 'Web Development Basics'\ndate: '2023-02-09'\nlastmod: '2023-02-09'\ntags: ['Web']\ndraft: false\n---\n\n\n\n> [Introduction | HTML & CSS Is Hard (internetingishard.com)](https://www.internetingishard.com/html-and-css/introduction/ 'Introduction | HTML & CSS Is Hard (internetingishard.com)')\n\n<TOCInline toc={props.toc} toHeading={2} />\n\n---\n\n## Introduction\n\n在开始我们的 Web 开发旅程之前,让我们先来聊一聊啥是 **Web**,希望能让大家先有一个感性的认知。首先,可以做这样一个比喻,Web 就是一个复杂的城市交通网络,Web 中的客户端,就像你在这座城市中的家,而服务器就像你想去的城市中的某个商店,那么就可以试着把一些 web 中的术语/组成部分放进这样一个 context 中:\n\n- 网络连接: 允许你在互联网上发送和接受数据,可以想象成是连接你家和商店的街道,它可以承载一定量的车流 (数据流)\n- **TCP/IP**: 传输控制协议 (_Transmission Control Protocol_) 和因特网互连协议 (_Internet Protocol_) 是定义数据如何传输的通信协议。这就像你去商店购物所使用的交通方式,比如汽车或自行车 (或是你能想到的其他可能)。相关的交通规则 (协议) 规定了什么样的车辆可以通行 (数据格式)、车辆该如何行驶 (数据如何被传递) ... 诸如堵车、车祸等意外情况在网络传输过程中也屡见不鲜 (不过,在网络世界里行驶,倒不需要你把科一到科四考一遍,哈哈)\n [https://en.wikipedia.org/wiki/Internet_protocol_suite](https://en.wikipedia.org/wiki/Internet_protocol_suite 'https://en.wikipedia.org/wiki/Internet_protocol_suite')\n- **DNS**: 域名系统 (_Domain Name System_) 服务器像是一本网站通讯录,记录了域名和 IP 地址的对应关系。当你在浏览器内输入一个网址时,浏览器获取网页之前将会查看对应的域名系统,将域名翻译为一个可识别的 IP 地址,只有这样浏览器才能找到存放你想要的网页的服务器,才能发送 HTTP 请求到正确的地方,这就像你确定了你要去的商店之后还需要知晓它的具体地理位置,并在地图上找到它的定位\n [https://developer.mozilla.org/zh-CN/docs/Learn/Common_questions/What_is_a_domain_name](https://developer.mozilla.org/zh-CN/docs/Learn/Common_questions/What_is_a_domain_name 'https://developer.mozilla.org/zh-CN/docs/Learn/Common_questions/What_is_a_domain_name')\n- **HTTP**: 超文本传输协议 (_Hyper Text Transfer Protocol_) 是一个定义客户端和服务端之间交流的语言的协议,属于**应用层**协议,比 TCP/IP 所处的**传输层**更高一层 (详见本文底部的 OSI 模型图)。这就像你在网购下订单时所填写的表单,详细说明了你的通讯方式、收获地址、商品信息 ... 在这个过程中你不需要担心商品具体是如何被运输的,只要和商家达成了交易并成功下单,就可以安心在家等待送货上门了 (这就是一种**抽象**!HTTP 作为更高层的抽象,不需要知道底层 TCP/IP 协议的实现方式,只要大家商量好不同层之间交流的形式 - 接口,之后各自做好自己分内的事就行了)\n- 组成文件: 一个网页由许多不同类型的文件组成,就像商店里不同类目的商品一样。这些文件大致可以分为两种类型:\n - 代码 : 网页大体由 HTML、CSS、JavaScript 组成,不过你会在后面的内容里看到更多不同的技术\n - 资源 : 其他组成网页的静态文件的集合,比如图像、音乐、视频、Word 文档、PDF 文件 ... 一旦确定之后就很少会发生改动\n\n\n\n> [https://developer.mozilla.org/zh-CN/docs/Learn/Getting_started_with_the_web/How_the_Web_works](https://developer.mozilla.org/zh-CN/docs/Learn/Getting_started_with_the_web/How_the_Web_works 'https://developer.mozilla.org/zh-CN/docs/Learn/Getting_started_with_the_web/How_the_Web_works')\n\n没事儿多逛逛 MDN ([https://developer.mozilla.org/](https://developer.mozilla.org/ 'https://developer.mozilla.org/')),在里面你能够看到对很多技术细节/名词的权威解读\n\n---\n\n经过了对 Web 的宏观性描述,接下来让我们再逐个深入 Web 世界里的一些专业名词和重要技术(为了保证意义的准确传达,以下内容保留了部分英文原版描述,相信各位大佬阅读起来应该也不会有太大障碍,的吧)\n\n## World Wide Web\n\n### Web Server\n\n网络服务器(Web server)可以代指硬件或软件,或者是它们协同工作的整体\n\n1. 硬件部分 (商场里存放商品的货架):一个网络服务器是一台存储了网络服务软件以及网站的组成文件(比如,HTML 文档、图片、CSS 样式表和 JavaScript 文件)的计算机。它接入到互联网并且支持与其他连接到互联网的设备进行物理数据的交互。\n2. 软件部分 (商场内部的商品库存管理系统,可与电商平台对接):网络服务器包括控制网络用户如何访问托管文件的几个部分,至少他要是一台 HTTP 服务器。一台 HTTP 服务器是一种能够理解 URL 和 HTTP 的软件。通过服务器上存储的网站的域名(比如 mozilla.org)可以访问这个服务器,并且他还可以将他的内容分发给不同用户的设备\n\n基本上,当浏览器需要一个 _托管_ 在网络服务器上的文件的时候,浏览器通过 HTTP 请求这个文件。当这个请求到达正确的网络服务器(硬件)时,HTTP 服务器(软件)收到这个请求,找到这个被请求的文档(如果这个文档不存在,那么将返回一个 404 响应), 并把这个文档通过 HTTP 发送给浏览器 (可以想象成是一个网购下单收货的过程)。在之后学习 Spring Boot 的时候,你将会对这一过程有更加深刻的理解。\n\n> [https://developer.mozilla.org/zh-CN/docs/Learn/Common_questions/What_is_a_web_server](https://developer.mozilla.org/zh-CN/docs/Learn/Common_questions/What_is_a_web_server 'https://developer.mozilla.org/zh-CN/docs/Learn/Common_questions/What_is_a_web_server')\n\n### Web Browser (Client)\n\n浏览器是一种通过 URL 获取 Web 资源并将其以某种可视化的方式展示在用户设备上的应用软件。在 Web 世界里,有一个叫**宿主环境**的概念,简单来说,它就是我们编写的 JavaScript 代码执行的具体环境,或者说是一种运行时环境 (runtime environment),而浏览器就是其中一种,除此之外还有像 [Node.js](https://nodejs.org/en/ 'Node.js') 等服务器端的宿主环境,感兴趣的同学可以自行了解\n\n更多关于浏览器的内容会在之后的 “浏览器中页面的渲染过程” 部分进行介绍\n\n### Uniform Resource Locators (URL)\n\na form of URI (_Uniform Resource Identifier_), provide a path to, or location of, a resource\n\n**Formats**\n\n- 一般格式: _Scheme_(protocol, e.g. http/https)://_DomianName/path_:_Port_\n- 特殊格式: _file://path-to-document_ (“file” indicates the documents resides on the machine running the browser)\n\nThe text _http\\://_ indicates that HTTP should be used to obtain the resource. Next in the URL is the server’s fully qualified **hostname** (e.g. [www.deitel.com](http://www.deitel.com/ 'www.deitel.com')) — the name of the web-server computer on which the resource resides. The hostname [www.deitel.com](http://www.deitel.com/ 'www.deitel.com') is translated into an **IP** address — a numerical value that uniquely identifies the server on the Internet. An Internet Domain Name System (**DNS**) server maintains a database of hostnames and their corresponding IP addresses and performs the translations automatically.\n\n**Tips**\n\n- If a server has been configured to use some other **port number 端口号**, it is necessary to attach that port number to the host name in the URL (e.g. :80 for HTTP, :443 for HTTPS)\n- **embedded spaces 空格** and (**; , &)** cannot appear in a URL (if San Jose is a domain name, it must be typed as San%20Jose, 20 is the hexadecimal ASCII code for a space)\n\n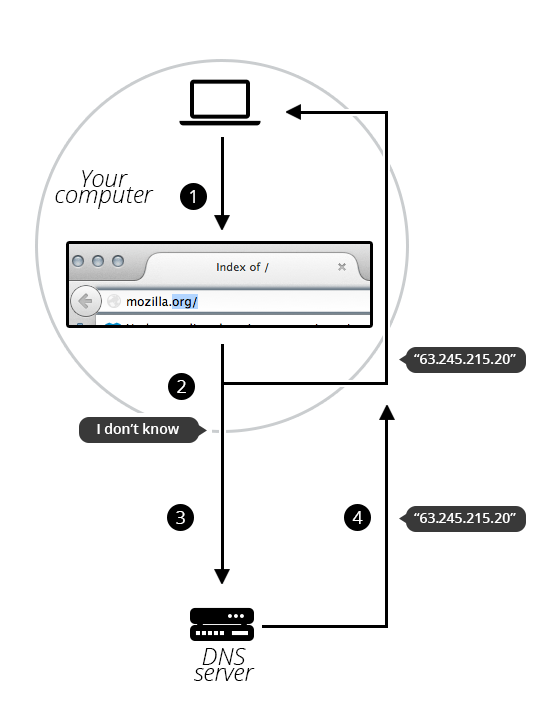\n\nSelf Learning: [URI, URL, URN 三者的关系与区别](https://stackoverflow.com/questions/4913343/what-is-the-difference-between-uri-url-and-urn 'URI, URL, URN 三者的关系与区别')\n\n### Path 路径\n\n**absolute path 绝对路径** a path that includes all directories along the way\n\n**relative path 相对路径** relative to some **base path** that is specified in the configuration files of the server\n\n**Tips**\n\n- [_http://www.gumboco.com/departments/_](http://www.gumboco.com/departments/ 'http://www.gumboco.com/departments/') (the ending slash means the specified document is a directory)\n- [_http://www.gumboco.com/_](http://www.gumboco.com/ 'http://www.gumboco.com/') (the server will search for _index.html_ at the top level of the directory)\n\n### Multipurpose Internet Mail Extensions (MIME) 文件类型\n\nspecifies the forms of documents received from a server (attached to the beginning of the document by server, servers determine the type of a document by using the file name extension as the key into a table of types)\n\n**form**: type/subtype (e.g. text/html, text/plain)\n\nSelf Learning: [https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/MIME_types](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/MIME_types 'https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/MIME_types')\n\n---\n\n相信现在的你对 Web 技术的全貌已经有了一定的了解,是时候深入 HTTP 这一 Web 的底层协议了 (Web 原理的精髓部分)。理解这个协议的细节无论对于前端开发还是后端开发都是十分重要的!\n\n不过,由于课程长度的限制,很多 HTTP 的衍生技术点无法在此逐个展开,感兴趣的同学可以移步相应内容下方的链接\n\n## Hyper Text Transfer Protocol (HTTP)\n\n超文本传输协议(HTTP)是一个基于 TCP 协议的用于传输超媒体文档(例如 HTML)的 **应用层协议**(作为最顶层的协议,它隐藏了很多网络层和传输层的细节,详见 Bonus 中的 OSI 模型)。它是为了约束/规范 Web 浏览器与 Web 服务器之间的通信而设计的,但也可以用于其他目的。HTTP 遵循经典的 **客户端-服务端模型**,客户端打开一个连接以发出请求,然后等待直到收到服务器端响应,就像两个人谈话一问一答的回合制形式。HTTP 是 **无状态协议**,这意味着服务器不会在两个请求之间保留任何数据(状态),即一般情况下服务器无法分辨多次请求的发起人分别是谁\n\n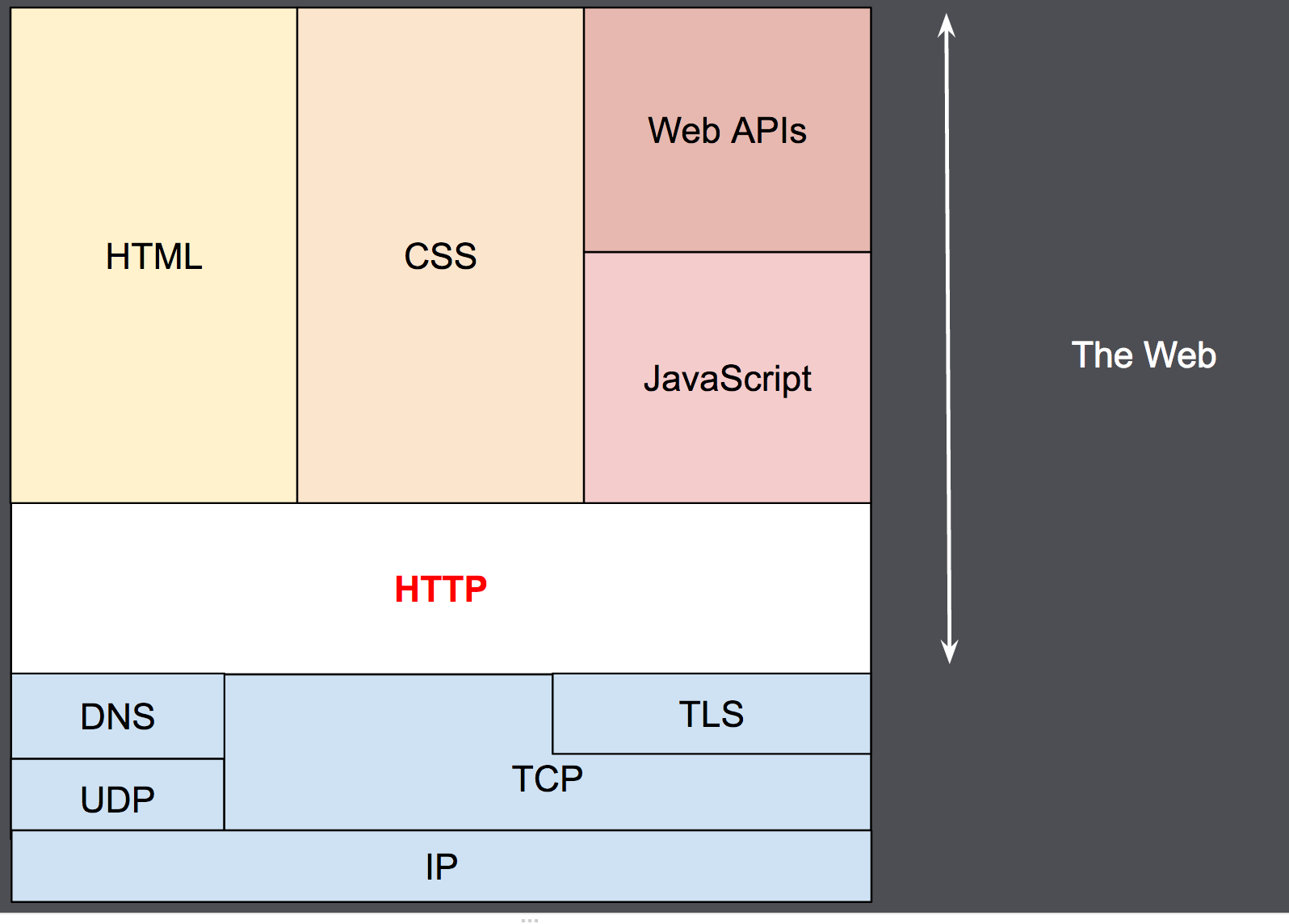\n\nSelf Learning: [https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Overview](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Overview 'https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Overview')\n\n**报文** 作为 HTTP 传输数据最重要的一种形式,有着自己的一套规范化的数据格式,让我们一起来看一下它们由哪些部分构成 (它就像我们平时对话时所使用的语言,有着自己的语法和语义,理解它对于你理解客户端服务端之间的信息交流非常有帮助)\n\n### Request Phase 请求报文\n\n- HTTP method, Domain part of the URL, HTTP version\n- Header fields\n- Blank line\n- Message body\n\n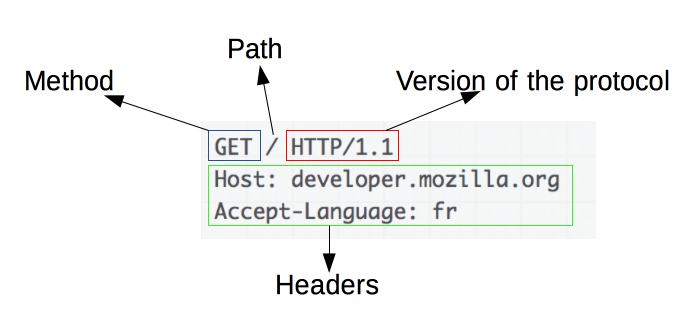\n\n### Request methods 请求方法\n\n| Method | Description |\n| ------ | ------------------------------------------------------- |\n| GET | Returns the contents of a specified document |\n| POST | Executes a specified document, using the enclosed data |\n| HEAD | Returns the header information for a specified document |\n| PUT | Replaces a specified document with the enclosed data |\n| DELETE | Deletes a specified document |\n\nSelf Learning: [https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods](https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods 'https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods')\n\n### Header fields 头部\n\n- **General 通用头部**: for general information, such as the date\n- **Request 请求头部**: included in request headers\n e.g.\n - _Accept: text/plain_ (specifies a preference pf the browser for the MIME type of the requested document)\n - _Host: host name_\n - _If-Modified-Since: date_ (specified that the requested file should be sent only if it has been modified since the given date)\n- **Response 响应头部**: for response headers\n- **Entity 实体头部**: used in both request and response headers\n\nSelf Learning: [https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers 'https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers')\n\n### Response Phase 响应报文\n\n- Status line (e.g. *HTTP/1.1 200 OK*)\n First digits of HTTP status codes:\n | First Digit | Category |\n | ----------- | ------------- |\n | 1 | informational |\n | 2 | success |\n | 3 | redirection |\n | 4 | client error |\n | 5 | server error |\n- Response header fields\n- Blank line\n- Response body (.html)\n\n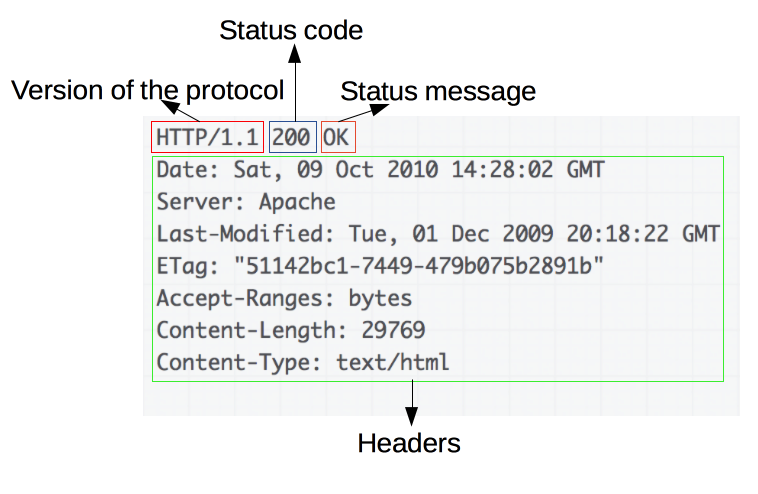\n\nSelf Learning: [https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status 'https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status')\n\n让我们把请求和响应的报文再放在一起比对一下\n\n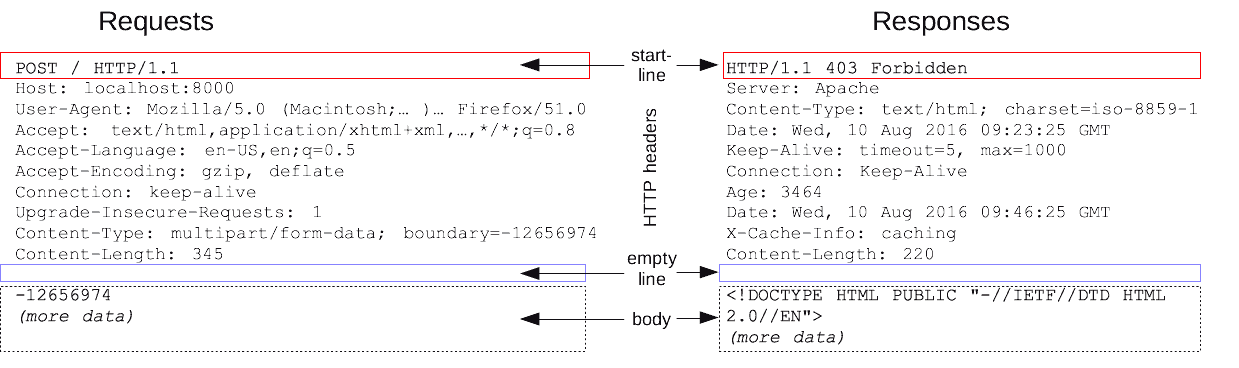\n\n### HTTPS\n\nHTTPS = HTTP + **SSL/TLS** (\\*Transport Layer Security**\\*) 会话层协议**\n\nHTTPS 有两个作用,一是确定请求的目标服务端身份,二是保证传输的数据不会被网络中间节点窃听或者篡改。\n\nHTTPS 是使用加密通道来传输 HTTP 的内容,即 HTTPS 首先会与服务端建立一条 TLS 加密通道。TLS 构建于 TCP 协议之上,它实际上是对传输的内容做一次加密 (非对称加密),所以从传输内容上看,HTTPS 跟 HTTP 没有任何区别。\n\nSelf Learning: [https://zh.wikipedia.org/wiki/超文本传输安全协议](https://zh.wikipedia.org/wiki/超文本传输安全协议 'https://zh.wikipedia.org/wiki/超文本传输安全协议')\n\n### Caching (HTTP 缓存)\n\n缓存是一种保存资源副本并在下次请求时直接使用该副本的技术 (空间换时间)。当 web 缓存发现请求的资源已经被存储,它会拦截请求,返回该资源的拷贝,而不会去服务器重新下载。对于网站来说,缓存是达到高性能的重要组成部分。同时,缓存需要合理配置,因为并不是所有资源都是永久不变的,重要的是对一个资源的缓存应截止到其下一次发生改变(即不能缓存过期的资源)\n\nSelf Learning: [https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Caching](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Caching 'https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Caching')\n\nHTTP 历史演进:HTTP/0.9 → HTTP/1.0 → HTTP/1.1 → HTTP/2.0 [https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP 'https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP')\n\n动手试一试:\n\n[https://developer.chrome.com/docs/devtools/network/](https://developer.chrome.com/docs/devtools/network/ 'https://developer.chrome.com/docs/devtools/network/') | chrome 浏览器的网络查看工具,按下 F12, magic happens !\n\n[https://hoppscotch.io/](https://hoppscotch.io/ 'https://hoppscotch.io/') | 超好用的在线抓包工具,看报文超方便 !\n\n> Programming the World Wide Web (8th edition)\n\n> Internet and World Wide Web How to program (2011)\n\n> [理解 HTTP 协议 | 被删的前端游乐场 (godbasin.github.io)](https://godbasin.github.io/front-end-playground/front-end-basic/front-end/front-end-10.html '理解 HTTP 协议 | 被删的前端游乐场 (godbasin.github.io)')\n\n---\n\n可能前面的这些内容会让你有一些 overwhelmed,不用担心,接下来我们就把这些知识点放置到 _浏览器渲染_ 这一实际场景中,将他们按照逻辑顺序串联起来,厘清他们之间的关系,并做一些适当的拓展 (此部分内容会涉及到一些前端三大件的内容,且当是给接下来的课程做一下预热吧,不完全理解也没关系)\n\n## 浏览器中页面的渲染过程\n\n实际上当我们在浏览器输入网页地址,按下回车键后,浏览器的处理过程是这样子的:\n\n1. DNS 域名解析(此处涉及 DNS 的寻址过程),找到网页的存放服务器\n2. 浏览器与服务器建立 TCP 连接\n3. 浏览器发起 HTTP 请求\n4. 服务器响应 HTTP 请求,返回该页面的 HTML 内容\n5. 浏览器解析 HTML 代码,并请求 HTML 代码中的资源(如 JavaScript、CSS、图片等,此处可能涉及 HTTP 缓存)\n6. 浏览器对页面进行渲染呈现给用户(此处涉及浏览器的渲染原理)\n\n进一步分析,我们可以将浏览器中页面的渲染过程分为两大部分 (详见 Bonus)\n\n- **页面导航**:用户输入 URL,浏览器进程进行请求和准备处理。\n- **页面渲染**:获取到相关资源后,渲染器进程负责当前标签页内部的渲染处理。\n\n对浏览器渲染的整体流程有了一定理解之后,我们再来深入看一看网页从 0 到 1 的生命周期吧\\~ (提前了解一下浏览器提供给我们的两个重要 API - DOM 和 BOM,任何前端框架的底层都离不开和这两个家伙打交道 ! 哦对了,还有浏览器的事件机制,一名合格的前端工程师应该掌握它 !)\n\n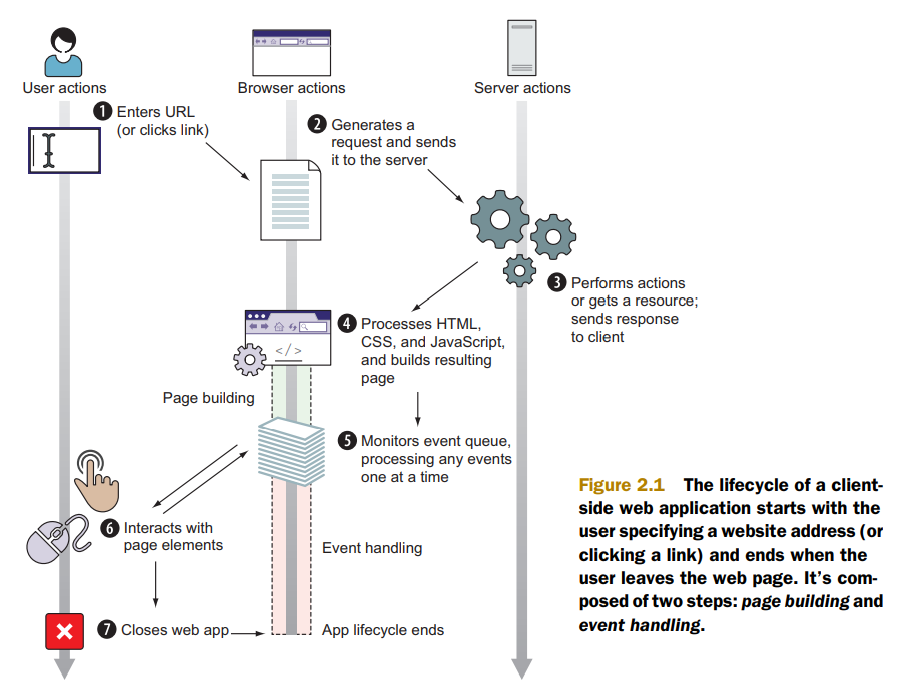\n\n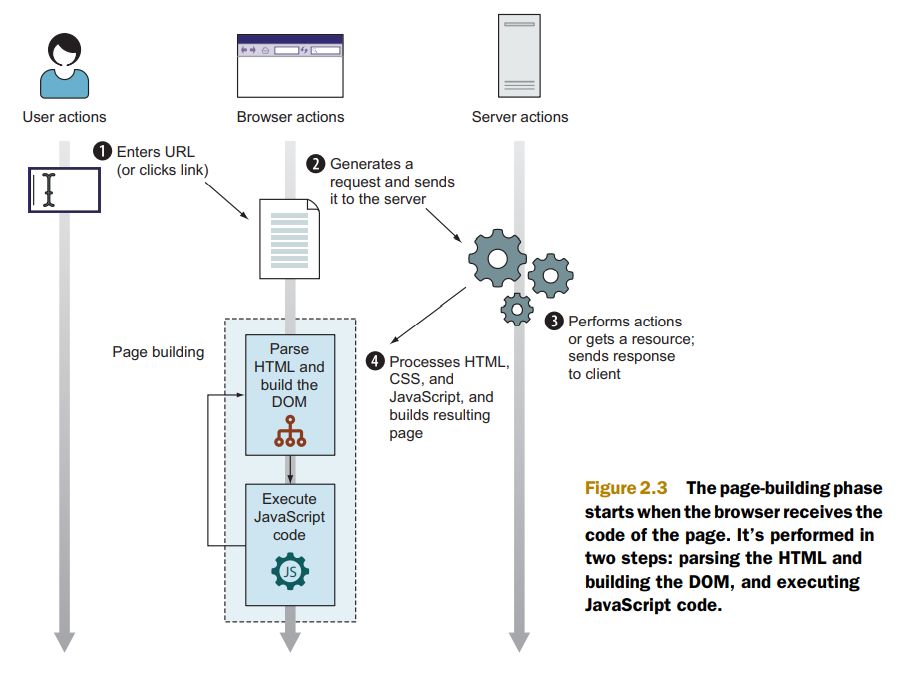\n\n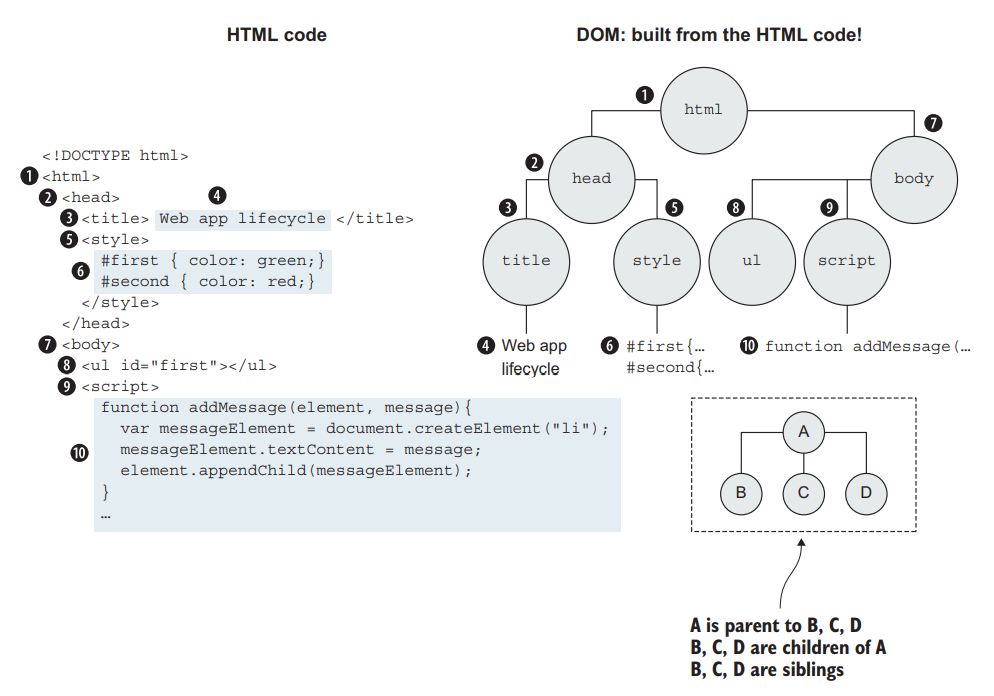\n\n浏览器对象模型(Browser Object Model),简称 **BOM**,表示由浏览器(宿主环境)提供的用于处理文档(document)之外的所有内容的其他对象 (浏览器在 JavaScript 中的表示形式)\n\n文档对象模型(Document Object Model),简称 **DOM**,将所有页面内容表示为可以修改的对象。`document` 对象是页面的主要“入口点”。我们可以使用它来更改或创建页面上的任何内容 (HTML 标签在 JavaScript 中的表示形式)\n\n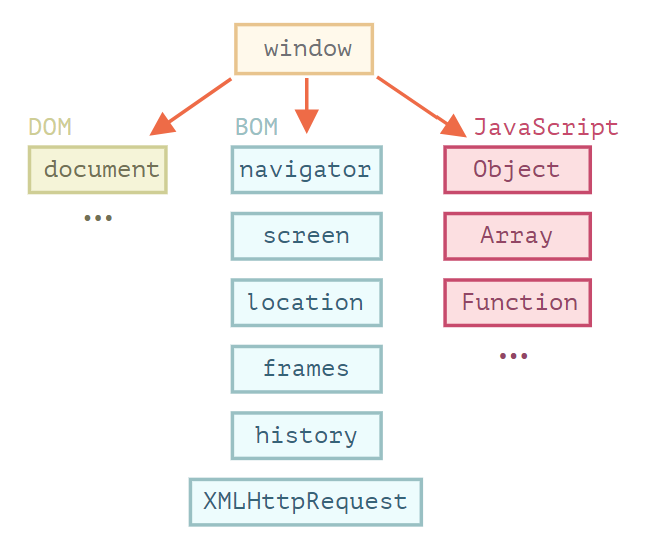\n\n动手试一试:\n\n按下 F12,在控制台 console 里敲入 window 或 document,看看会出现什么\n\nSelf Learning: [https://developer.mozilla.org/zh-CN/docs/Web/API/Document_Object_Model/Introduction](https://developer.mozilla.org/zh-CN/docs/Web/API/Document_Object_Model/Introduction 'https://developer.mozilla.org/zh-CN/docs/Web/API/Document_Object_Model/Introduction')\n\n\n\n**Events 事件 (Event-driven 事件驱动)**\n\n- **Browser events**, such as when a page is finished loading or when it’s to be unloaded\n- **Network events**, such as responses coming from the server (Ajax events, server-side events)\n- **User events**, such as mouse clicks, mouse moves, and key presses\n- **Timer events**, such as when a timeout expires or an interval fires (setTimeout, setInterval)\n\nSelf Learning:\n\n[https://zh.javascript.info/introduction-browser-events](https://zh.javascript.info/introduction-browser-events)\n\n[https://zh.javascript.info/event-loop](https://zh.javascript.info/event-loop)\n\n> Secrets of the JavaScript Ninja, (Second Edition) - JOHN RESIG BEAR BIBEAULT and JOSIP MARAS\n\n> [https://zh.javascript.info/browser-environment](https://zh.javascript.info/browser-environment 'https://zh.javascript.info/browser-environment') | 学习 JavaScript,有这一个网站就足够了\n\n---\n\n## Bonus\n\n加餐环节,按需食用\\~\n\n### 软件架构设计模式\n\nMVC (Model View Controller)\n\nMVP (Model View Presenter)\n\nMVVM (Model View View-Model) (现代前端工程师必须了解的 View-Model 双向绑定)\n\n[https://github.com/livoras/blog/issues/11](https://github.com/livoras/blog/issues/11)\n\n### World Wide Web Consortium (W3C)\n\n作为 Web 领域的布道者以及标准制定者,W3C 组织是每一个 web programmer 都应该知晓并了解的组织。尽管 web 编程相对来说更为自由和开放,但是若没有统一的标准来约束不同技术的创造者和使用者,那么这种 freedom 将会变成一种令人苦恼的 chaos\n\n职责与使命\n\n- devoted to developing non-proprietary, interoperable technologies for the World Wide Web.\n- make the web universally _accessible_—regardless of disability, language or culture. The W3C home page ([www.w3.org](http://www.w3.org 'www.w3.org')) provides extensive resources on Internet and web technologies.\n\n标准制定\n\nWeb technologies standardized by the W3C is called **Recommendations (这些标准并非强制性的)**. Current and forthcoming W3C Recommendations include the Hyper-Text Markup Language 5 (_HTML5_), Cascading Style Sheets 3 (_CSS3_) and the Extensible Markup Language (_XML_). A recommendation is not an actual software product but a document that specifies a technology’s role, syntax rules and so forth.\n\n> [https://www.w3.org](http://www.w3c.org 'https://www.w3.org')\n\n### 页面导航过程\n\n当用户在地址栏中输入内容时,浏览器内部会进行以下处理:\n\n1. 首先浏览器进程的 UI 线程会进行处理:如果是 URI,则会发起网络请求来获取网站内容;如果不是,则进入搜索引擎\n2. 如果需要发起网络请求,请求过程由网络线程来完成。HTTP 请求响应如果是 HTML 文件,则将数据传递到渲染器进程;如果是其他文件则意味着这是下载请求,此时会将数据传递到下载管理器\n3. 如果请求响应为 HTML 内容,此时浏览器应导航到请求站点,网络线程便通知 UI 线程数据准备就绪\n4. 接下来,UI 线程会寻找一个渲染器进程来进行网页渲染。当数据和渲染器进程都准备好后,HTML 数据通过 IPC (Inter-process Communication) 从浏览器进程传递到渲染器进程中。\n5. 渲染器进程接收 HTML 数据后,将开始加载资源并渲染页面\n6. 渲染器进程完成渲染后,通过 IPC 通知浏览器进程页面已加载\n\n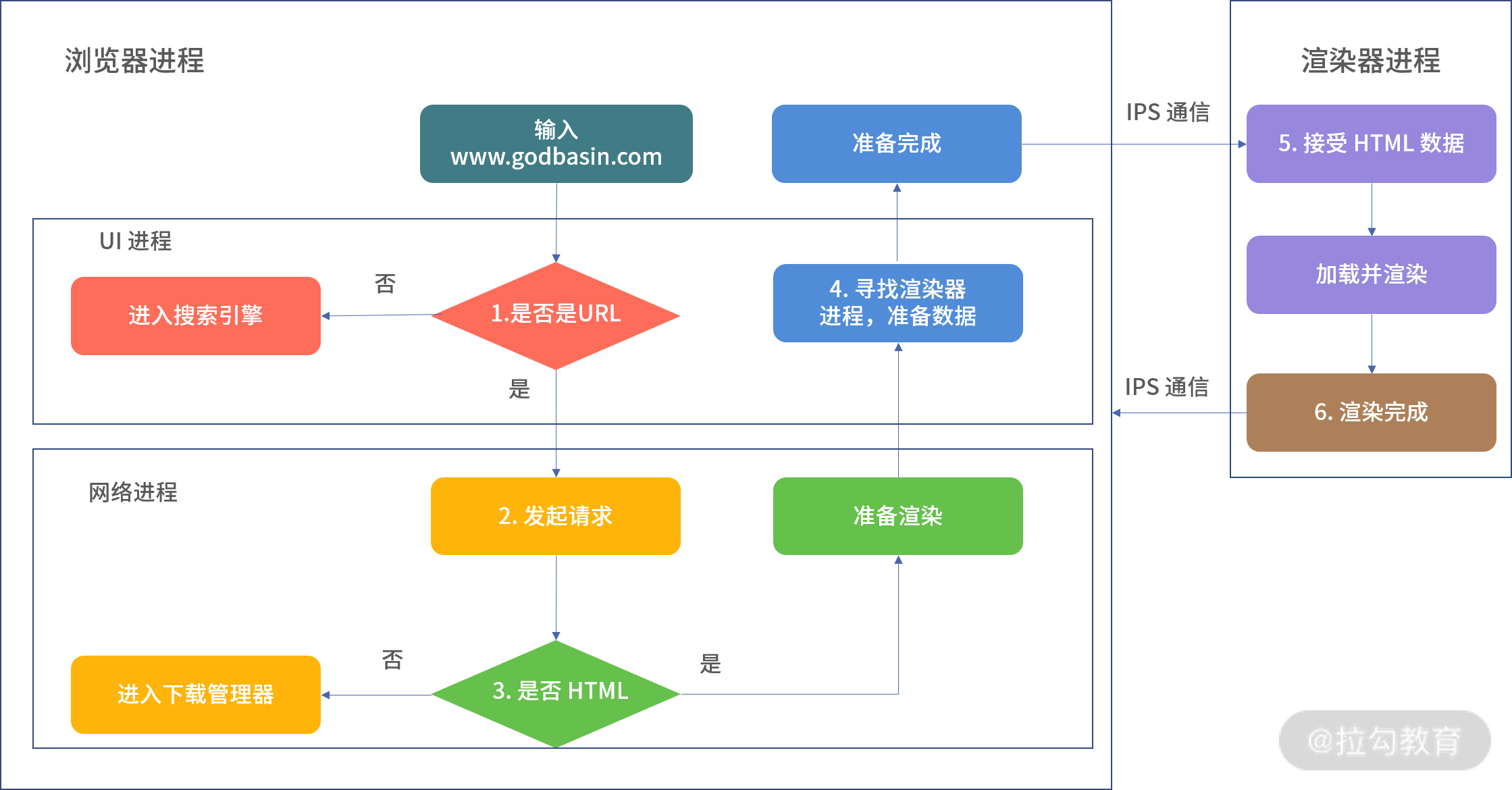\n\n### 页面渲染过程\n\n1. 解析 (Parser):解析 HTML/CSS/JavaScript 代码。\n2. 布局 (Layout):定位坐标和大小、是否换行、各种 position/overflow/z-index 属性等计算。\n3. 绘制 (Paint):判断元素渲染层级顺序。\n4. 光栅化 (Raster):将计算后的信息转换为屏幕上的像素。\n\nSelf Learning: [https://coolshell.cn/articles/9666.html](https://coolshell.cn/articles/9666.html 'https://coolshell.cn/articles/9666.html')\n\n### OSI (Open Systems Interconnection) 七层网络模型\n\n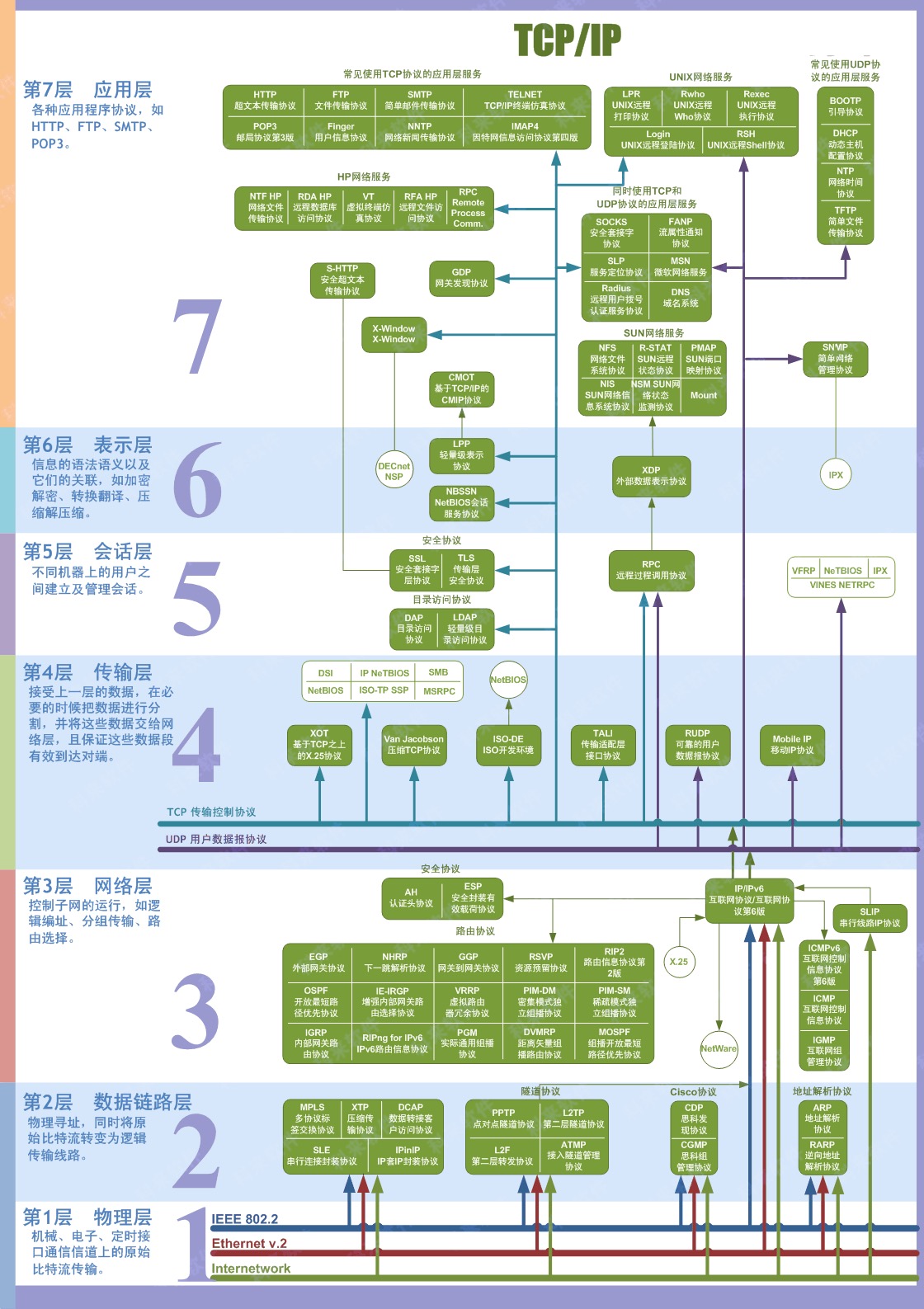\n",
"attributes": [
{
"value": "web-dev-basics",
"trait_type": "xlog_slug"
}
]
}

